

A secret third way: Likelihoodist statistics
A tutorial on designing and reporting experiments in the most objective framework
The law of likelihood explains how to interpret statistical data as evidence
- Royall, 2000GOAL
I provide a step-by-step guide on designing an experiment within the likelihoodist (evidential) framework. It’s impossible to condense an entire framework within a single post, so I’ll simply walk through the steps, provide explanations of key concepts, and link to relevant readings. As a caveat, I’m quite new to this approach, so there might be bits I got wrong; I welcome feedback and comments.
WHY CONSIDER LIKELIHOODIST INFERENCE?
Every framework has its own pros and cons. Here are some for Likelihoodist methods:
Likelihood ratios (LR) are an objective measures of evidence between competing hypotheses
Inferences are based only upon the evidence provided by the observed data
Does not require specifying a prior (subjective) probability
LRs and Support values from independent studies can be added together easily and directly, i.e., merge studies
Data can be analysed sequentially without needing to adjust for the number of (un)planned looks
Compare multiple hypotheses without increasing the likelihood of misleading evidence by much
Post hoc and exploratory hypotheses can be tested after the experiment is over
Add more data (beyond planned N) to improve precision without penalty
Setting up an experiment
As with all research, we need to decide on the goal of an experiment. Royall (1997) summed up the outcome of data collection as attempting to answer one of three questions:
What should I do now?
What should I believe now?
How should I treat the data as evidence for one theory rather than another?
Likelihoodist focuses on answering (3), providing a framework for objectively quantifying the relative evidence in favour of one hypothesis over another. Unlike NHST (which answers 1), it doesn’t tell you how to “act” (behavioural induction), and unlike Bayesian (which answers 2), it does not tell you what to believe. Likelihoods are a way of using the available data to assess the strength of evidence for various hypotheses of interest. As such, it is very important to be specific with what you are interested in comparing.
Hypotheses
When planning an experiment you *must* define at least two simple hypotheses (technical term). This is the first departure from NHST, where we typically employ compound hypotheses (e.g., H1 != 0, which include *all* non-zero values). In Likelihoodist, you must specify single values, e.g., H1 = 2 points.
The second departure from NHST is that you are specifying the size and direction of the predicted effect. These can be see as directional hypotheses (“one-tailed”, but not the same thing as there is no tail). Some might be put off by this and say “how am I supposed to know what the true effect is before I do the study?” This is a fundamental problem of doing research. However, we can take a few principled approaches. We can rely on our knowledge and existing research on a topic, which might exclude some values or make some more likely. We can use a minimum value that we deem to be theoretically/clinically/practically relevant; this is akin to setting a SESOI in NHST power analyses. Or we can use the observed data and take the maximum supported value, treating the sample effect = population effect (i.e., the MLE).
Another note on setting the expected effect size, due to the nature of the likelihood function, the maximum support for a given hypothesis (e.g., H1 = 2) will actually be when the observed effect is near but slightly higher than the predicted effect size (e.g., MLE = 2.4; Cauhsac, 2020). Thus, we should set our predicted effect slightly lower than our expectation of the real effect. OK, what would this look like in practice?
Effect size
Given the above, my naïve approach would be as follows: if I am new to an area, I might rely on meta-analyses that provide distributions of obtained effects as a rough guide. In Social Psychology, this tends to be a Cohen’s d = .40. Thus, I will take this as my best guess for the predicted effect. However, I know the best support for my effect will be if I slightly underestimate this effect (which will also increase my sample size; never a bad thing if resources are available). But, by how much?
Another phenomenon in social psychology is the crud factor (see Orben & Lakens, 2020). Things tend to be related to other things. An often-cited size for this is d < .20. Effects smaller than this value - while still of potential importance - should be viewed with scepticism as they might just be crud. Thus, for a new experiment, a good place to start is .20 < d < .40. Arbitrarily, I will go with d = .35.
H0 vs H1
Now that we have a predicted effect size, we can set the hypotheses. Remember, they have to be simple hypotheses:
We designed an experiment to compare the relative evidence for the true population effect being either 0 or 0.35.
Sample size planning
The next hurdle is determining an appropriate amount of data to collect. With NHST, this is usually estimated using a power analysis. However, in Likelihoodist we don’t have Type I and Type II error probabilities, as we’re only using the Law of Likelihoods for our inferences; no external probabilities allowed!
Thankfully, there have been developments in this area as well. I actually decided to write this post because of a paper I came across that provides an R package to compute sample sizes for simple experiments (Cahusac & Mansour, 2022). The {likelihoodR} package offers a function to estimate a sample size for a paired-samples t-test*. Using this we can estimate the sample size for our study. However, before we can do that we need to discuss the two type of errors in Likelihood experiments.
Misleading and Weak evidence (M0 and M1+W1 error)
Unlike NHST, where the errors stem from long-run probabilities, in Likelihoodist these are a product of the likelihood function. Two main forms of errors are often discussed in the literature. Misleading evidence (M) refers to the probability that we obtain S ≥ k but in the wrong direction (S is the support level and k is our threshold for evidence). Weak evidence (W) refers to the probability that even when we record 100% of our target sample S < k, that is, we never reach our target support level.
Misleading evidence for H0 (M0) can be seen as akin to Type I error. With moderate sample sizes this tends to not be a problem (assuming a normal CDF, for S = 2, M0 = .023, for S = 3, M0 = .007), and decreases as sample size increases (i.e., M0 → 0 as n → ∞), so it should be of no worry in a practical sense to most researchers that tend to collect N > 10.
The combined misleading evidence for H1 (M1) and weak evidence for H1 (W1), M1+W1, is seen as akin to Type II error (e.g., M1+W1 = .20 is similar to β = .20 (power = .80)). Thus, when planning our sample size, we concern ourselves with the probably of misleading and weak evidence in favour of our primary hypothesis (H1).
Support level
The last thing we need to decide is the indices we use to make inferences. The two main ones are the Likelihood Ratio (LR) (not to be confused with G-tests), and the Support level (the natural log of LR, ln(LR)). Both provide the same information but some prefer the latter due to it varying from −∞ to +∞, with 0 being equal evidence (same as LR = 1). The lowest support level, S, that you should use is S = 2. This is equivalent to an LR = 7.4. We can interpret an LR10 = 7.4^ as H1 is 7.4 times more likely than H0.
Estimating sample size
Now we have all the ingredients. I’ll use the function L_t_test_sample_size() to estimate the necessary sample size for a study with the criteria: d = .35, M1+W1 = .20, S = 2. This is the minimum rigorousness I’d tolerate. (NB: Cahusac says “it would be prudent to use a larger [threshold, S] of say 3” p. 46, and sets M+W = .05)
# Sample size estimate for a paired-samples t-test
L_t_test_sample_size(MW = 0.20, sd = 1, d = 0.35, S = 2, paired = TRUE)
For 1 sample, or related samples, t test with M1 + W1 probability of 0.2
Strength of evidence required is 2, and effect size of 0.35
Required sample size = 75N = 75 is our target sample size. The equivalent for an NHST paired t-test would be N = 67 (two-tailed) or N = 52 (one-tailed)**. This is slightly bigger than the NHST approach, but so would a Bayesian t-test (the de facto replacement these days), N = 100 (two-tailed; Cauchy JZS prior, BF = 3) or N = 84 (one-tailed).
Run the experiment
We’ve sorted our H0 and H1, our acceptable levels of M+W error, our evidence threshold S, and our sample size; all the info we need to preregister the study on OSF and begin data collection.
Collect data
Let’s simulate some data. I’ll go with N = 80. I imagine a happiness experiment testing participants’ mood before and after an intervention.
library(faux)
# Data simulated
happiness <- sim_design(
within = list(mood = c("pre", "post")),
r = 0.5, # explicit reminder that power analyses assume a corr. b/w measures
mu = c(pre = 1, post = 1.35),
sd = c(pre = 1, post = 1.1),
n = 80)Let’s see what the data looks like:
get_params(happiness)
n var pre post mean sd
1 80 pre 1.00 0.49 1.16 1.04
2 80 post 0.49 1.00 1.71 1.09plot(happiness)
Likelihood analysis
Now the fun part. We can analyse our data using Likelihoodist methods. We have two ways of doing this. We can use the {likelihoodR} package, which provides summary statistics and a plot by default, or we can use the Jamovi {jeva} module. I recommend the latter, as the package seems to not be getting much support and the results are a bit different from the Jamovi output. I haven’t computed the values manually to see which is more appropriate [if a reader want’s to, please comment your findings!]
{likelihoodR} package
Once you have the data in R, you can run this command:
L_ttest(happiness$pre, happiness$post, null=0, d=0.35, L.int=2, supplot=-10)This will produce the following output (plot is the same in Jamovi). It also reports a t-value, p-value (two-tailed), and the standardised effect size, d.
Maximum support for the observed mean 0.5511605 (dashed line) against the null 0 (black line) = 9.39
Support for d of 0.35 (0.3773849, blue line) versus null = 8.352
S-2 likelihood interval (red line) is from 0.30854 to 0.79378
t(79) = 4.572, p = 1.762e-05, d = 0.511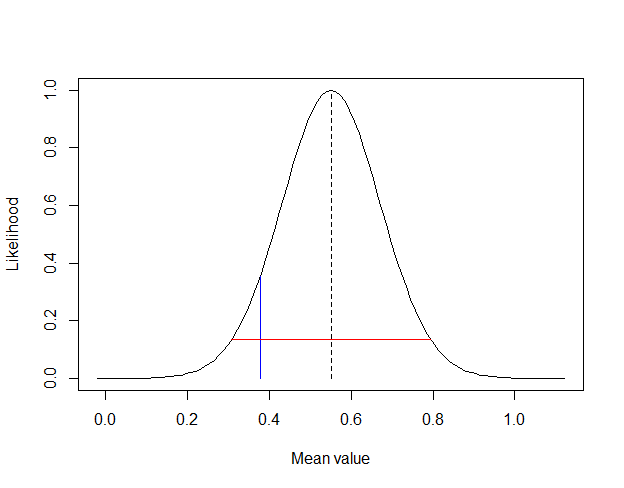
The plot is of the likelihood function for the data, the dashed line is the Maximum Likelihood Estimate (MLE; the best supported parameter value in our data), the blue line is our H1, and the red horizontal line is the S-2 support interval. There is also a line for H0 (at 0), but it’s too small to see.
Jamovi {jeva} module
The {jeva} modules provides a bit more functionality for analysing various designs. I won’t go into it, but there is a blog on their website about it here.
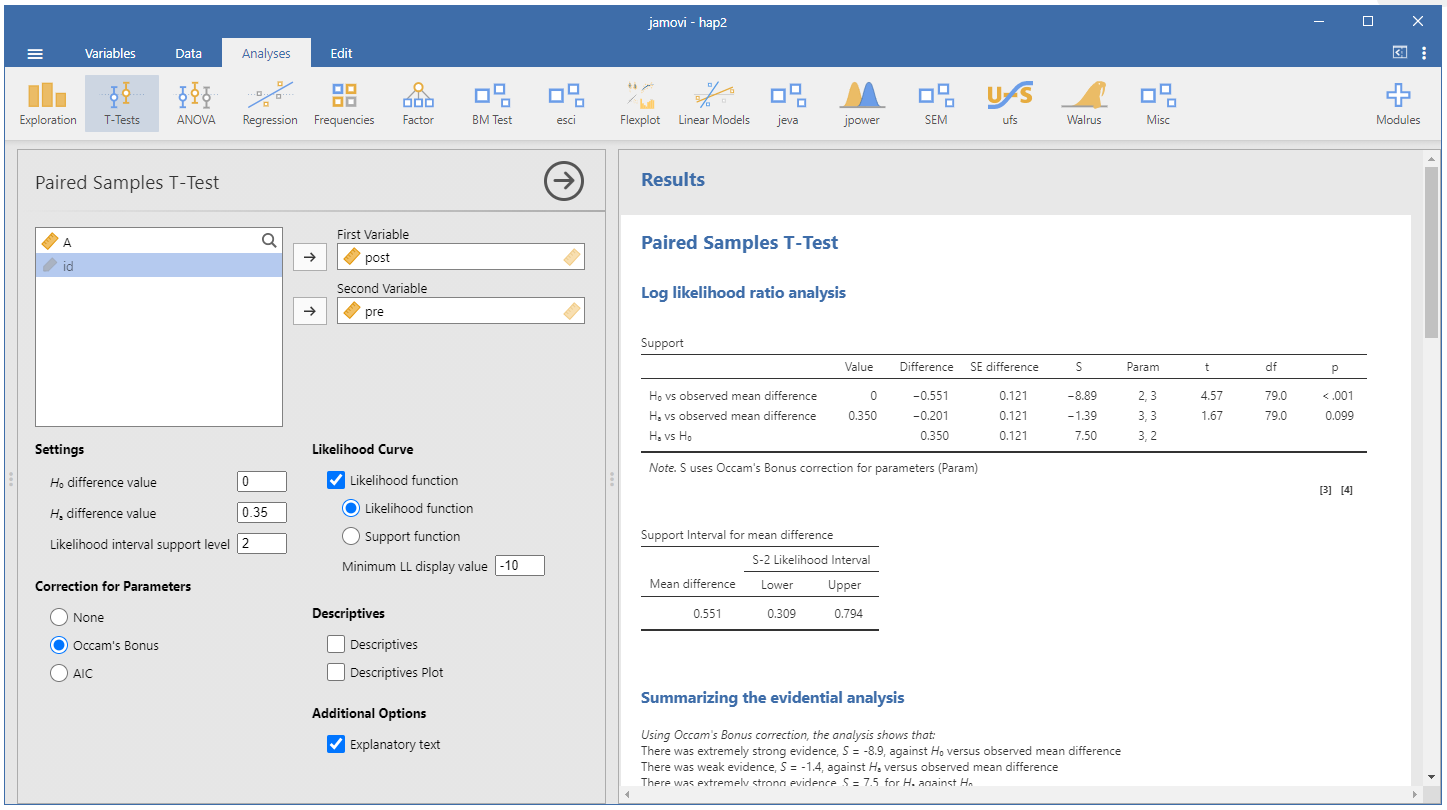
In the image you see the overall look of the package and the settings necessary. Importantly, the order you enter the data matters as it is subtracting values, so a negative Mean difference will result in a different LR than a positive Mean difference. I also selected the Likelihood function plot and the Explanatory text. For parameter corrections I can’t say much as it is beyond my current level of knowledge; Occam’s Bonus is selected by default. Do note that the LR are different from what the {likelihoodR} produces (even with the correction off, might be due to the function taking the SMD while jeva taking the raw value 🤷♂️).

In the table we see three comparisons. H0 vs. MLE (0 vs. 0.55), H1 vs. MLE (0.35 vs. 0.55) and, our comparison of interest, H0 vs. H1 (0 vs. 0.35). The result of our main LR indicates there is relatively more support for an population effect size of d = .35 than d = .00, S = 7.50. You can also see the Support Interval as S-2 [0.31, 0.79]. The output also provides a nice explanation and interpretation of key values.
Interpretation and write-up
We can combine the data and the results and write something like this:
“Participants post intervention (M = 1.71, SD = 1.09, n = 80) showed improved mood compared to pre intervention (M = 1.16, SD = 1.04, n = 80), increasing the mean self-reported rating by 0.55 points (d = 0.51). The support of S10 = 7.5 indicates extremely strong evidence for a theoretically relevant effect (H1) relative to no effect (H0) of the intervention. The S-2 likelihood interval was between 0.31 and 0.79 scale points.”
If you want, you can also mention there is extremely strong evidence for the MLE against H0, SM = 8.9 (this is known as the maximum likelihood ratio, it is akin to the p-value as it represents evidence against the null). Reporting the MLE and the SM is typical practice, and can also be used in naive/exploratory research where the size and direction of an effect cannot be easily predicted a priori. It is also reported if your observed effect (MLE) is nowhere near your predicted effect (H1).
Support Interval
In the plot and in my write-up, I make mention of the S-2 support interval. This is an interval around the MLE that contains all parameter values that are best (and equally) supported by the data at a given level of support, k, called formally the 1/k likelihood support interval. All values within it are better supported by the data than values outside it (which themselves become increasingly unlikely the further out they lie); the values contained within the S-2 are no more different in level of support that S = 2 (7.4 times) from the MLE. It is particularly useful when you don’t have a specific hypothesis to compare to and/or want to see if a relevant effect size is included in it, or to gauge your level of precision (i.e., more data needed). An S-2 interval is close in width (and interpretation) to a 95% CI in NHST.
Small note, an S-3 interval will be wider and less precise than an S-2 interval. Initially, I assumed the k value represented how strongly values in the interval are supported by the data, but it’s the inverse, it’s “what values are not more than k times less likely than the MLE”. S-2 implies those range of values are not more than 7.4x (e^2) more different than the MLE, while S-3 (e^3) that the range of values is not 20.1x more different than the MLE (so less precision).
Sequential analysis (only collect what you need)
Although we specified a target N, nothing is stopping us from analysing the data as it comes in and just stop when we reach S > k. Yes, you can stop early! This is a huge advantage of the likelihoodist approach, especially when budget and ethical constraints are substantial. This is called stopping for efficacy when S10 > k (i.e., the alternative is better supported over the null) and inefficacy when S01 > k (i.e., the null is better supported over the alternative).
Futility
Sometimes you have limited resources and little insight regarding your pet hypothesis. Therefore, you might ask “with the resources I have, can I even obtain sufficient evidence for/against my prediction?” The inability to (ever) reach the evidence threshold for either H0 or H1 is called futility. If you could collect large amounts of data, then this isn’t a concern, as the probability of eventually finding sufficient evidence is 1. OK, but what about with your sample size? You can use the LR you obtain at the interim analysis, LR_interim, and compute the conditional probability that you will obtain your desired LR at the end, LR_end, by figuring out if the remaining sample could produce the difference in LR needed (see Blume & Choi for the calculations). This can save you a lot of time and money.
Collecting more data (allowed!!!)
Another benefit of the likelihoodist approach is that we are allowed to collect more data if our estimates and/or support level are too imprecise. Even if 100% of the planned sample size is collected, if after the analysis we see the data are not very insightful we can just collect more and add it to the analysis! This is a stark contrast to the NHST approach, where adding more data in such a manner is forbidden or would require a priori corrections.
Now, you might say “but what if the null is actually true? won’t I just get a false positive at some point?'“ NOPE, likelihood ratios will always converge on the true parameter value as data increases; even if you ignore all evidence in favour of H0 and aim to stop only when you obtain evidence for H1, the probability that your data collection will never end is >(1 − e^−S) (i.e., 86% for S = 2, and 95% for S = 3).
Post-hoc hypotheses (also allowed!!!)
Unlike NHST, likelihoodists have the benefit of interrogating hypotheses that were not pre-specified with only a minimal increase in error (called the probability of being led astray; Blume & Choi, 2017).
In fixed sample-size designs (only look at target N), this is equivalent to the M1 error. According to Blume “there appears to be little penalty for evaluating post-hoc alternatives hypotheses in fixed sample size designs” (p. 8). This means that you are free to specify new hypotheses that are of interest (e.g., H2, H3,…) without worrying about increasing your error rate! No more HARK-ing!
In sequential designs (where we can look at the data as it comes in, but set a minimum n before we look, m0, and a maximum N to stop collecting, m) we are also allowed to investigate alternative hypotheses, but the error is more complicated to estimate as it depends on the sample constraint ratio m/m0. I’ll copy this table from Blume which shows some of the led astray error rates for some common evidence ratios:

From the table, we see that at LR = 8 (S ≈ 2) you can look when 20% of the data is collected to have only 8.18% error of finding sufficient evidence for our pet theory instead of the true null, while for the higher evidence ratios, 10% is sufficient to have a reasonably low, 5-6%, error rate (recommended by Blume).
Final thoughts
The likelihoodist approach seems to be the forgotten middle child of statistics. It is mentioned in passing, but not really appreciated or given enough love. I hope this guide can incentivise some to consider it in their future projects, even if just a fun teaching tool with students to see which of the three approaches they find most intuitive. At present, I would not switch to this as my daily driver, mostly due to a lack of available software to do analyses for complex designs. But, maybe in a few years this will be the new contender in the #statswars.
Notes
^Read 1-0, not 10; it’s like a Bayes Factor, BF10, comparing H1 vs H0.
*The function also can estimate independent-samples t-test, however, I am unsure if the values it provides are accurate. In the paper, Cahusac says that LR tests tend to require 20% more participants than their equivalent NHST tests, however, this does not seem to match the output of the results. If you use:
L_t_test_sample_size(MW = 0.20, sd = 1, d = 0.4, S = 2, paired = FALSE)
For independent samples t test with M1 + W1 probability of 0.2
Strength of evidence required is 2, and effect size of 0.4
Required total sample size (n1 + n2) = 118This estimates you need N = 118, n = 59 per group. The equivalent in NHST would require N = 200, n = 100 per group. I believe there might be an error either in the code or in the reporting (however, in his paper, the value reported for the total N is the one the function currently produces). I have emailed the author for clarification and will update this post when I hear back.
**I report both two-tailed and one-tailed NHST sample sizes as this is a second point of confusion on what the {likelihoodR} package is doing. In the package paper, all comparisons are made against one-tailed tests - which seem logical to me given that Likelihoodist hypotheses are directional - however, in the paper Cahusac (2023), and in the t-tests output, the package computes the results as two-tailed. I have asked the author about this issue also.
References
Blume, J. D., & Choi, L. (2017). Likelihood Based Study Designs for Time-to-Event Endpoints. https://doi.org/10.48550/arXiv.1711.01527
Cahusac, P. (2023). Log Likelihood Ratios for Common Statistical Tests Using the likelihoodR Package. R J., 14(3), 203-213.
Cahusac, P. M. (2020). Evidence-Based Statistics: An Introduction to the Evidential Approach-from Likelihood Principle to Statistical Practice. John Wiley & Sons.
Cahusac, P. M., & Mansour, S. E. (2022). Estimating sample sizes for evidential t tests. Research in Mathematics, 9(1), 2089373. https://doi.org/10.1080/27684830.2022.2089373
Orben, A., & Lakens, D. (2020). Crud (re) defined. Advances in Methods and Practices in Psychological Science, 3(2), 238-247. https://doi.org/10.1177/2515245920917961
Royall, R. M. (1997). Statistical evidence: A likelihood paradigm. Chapmen & Hall.
Royall, R. M. (2000). On the probability of observing misleading statistical evidence. Journal of the american statistical association, 95(451), 760-768.
This is an excellent introduction and overview to the evidential/likelihood approach. Well done!